こんにちは、ウェブ系ウシジマくんです!今回の記事では、Rubyを扱うのなら習得が必須となる正規表現について取り上げます。
正規表現とは、文字列を検索する時に便利な記号のようなもの。
実はRubyに限らず、PHPやJavaなど他の言語でも応用できる(言語によって微妙に書き方は異なりますが)のも特徴。
文字列処理が得意なRubyで正規表現を習得すれば、よりコードを書くスピードが上がるので仕事のできるエンジニアになれるでしょう!
今回の記事の対象者
- Rubyで正規表現を覚えたい人
- エディタでの検索と置換をもっとスピーディに行いたい人
- 正規表現の記号が呪文のように見えてしまう人
Rubularで試しながら正規表現の習得スピードをアップしよう
正規表現を習得するためには、実際に書いて覚えるのが一番です。でも、その度にテキストエディタをいちいち立ち上げてコードを書くのは面倒ですよね?
そこで役立つのが
これはWebブラウザで使えるオンラインツールで、それぞれのメタ文字の意味をスピーディーに確認できるので便利。
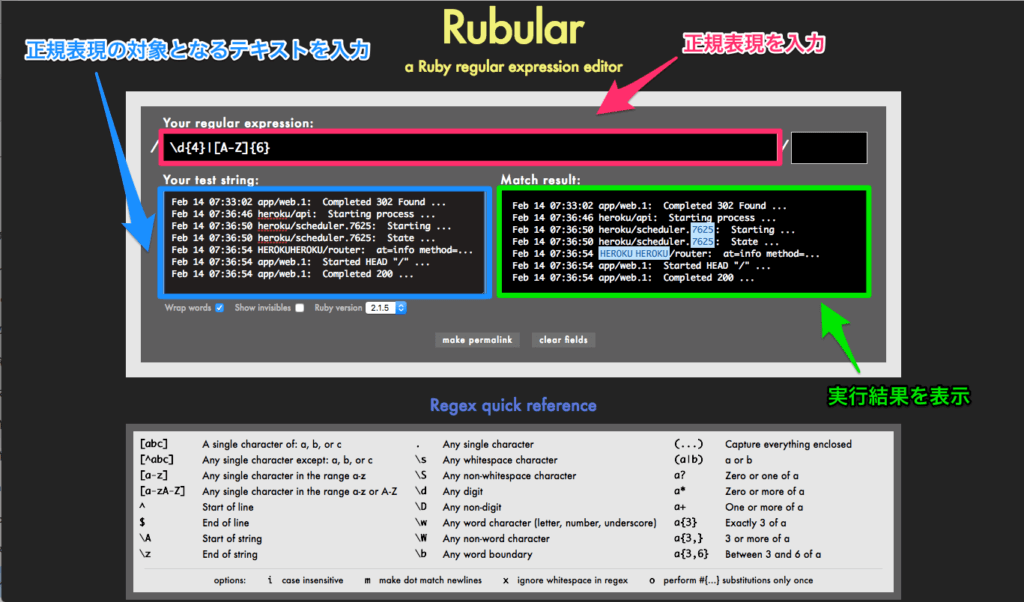
使い方は上記の画像のように非常にシンプル。いつでも開けるようにしておけば、それぞれのメタ文字を忘れてしまっても安心ですよね。
覚えておきたい正規表現の基礎
それではここから、小見出しごとに正規表現を紹介して行きます。
ここにあるメタ文字をただ眺めているだけでは絶対に身につけることはできないので、実際に打ち込みながら試して見てください。
そのために、ブラウザ上でコードを実行できるPaiza.ioを用意しました。
実際に打ち込みながら試してみてくださいね!
まずは21個のメタ文字やベーシックな正規表現から!〜初級編〜
1個の半角数字にマッチする
\d #半角数字を表すメタ文字
[0-9]
\dと[0-9]はどちらも同じ意味をなす正規表現です。
半角数字は、0,1,2,3,4,5,6,7,8,9のいずれかなので、そのどれかにマッチできるということですね。
同じメタ文字の仲間である{}を使って(後述します)\dの直後に{2}のように数字を入れると、桁数を表現することができます。
つまり、\d{2}とすることで、2桁の半角数字にマッチするという意味になります。
ちなみに、\d{2,4}とすると、2桁または4桁の半角数字にマッチするという意味に。
以下では、090-1234-5678という架空の携帯番号に\dのメタ文字を使うことでマッチさせています。
# <<~TEXT..TEXTの部分はヒアドキュメント
text = <<~TEXT
090-1234-5678
TEXT
# //がrubyでのREGEXPクラスのインスタンス
# scanメソッドは引数に指定した正規表現のパターンとマッチする部分を文字列からすべて取り出し、配列にして返す。
# マッチする部分がなければ、空の配列を返します。
# //の中に正規表現を入力してください。
p text.scan(/\d{3}-\d{4}-\d{4}/)
#=>["090-1234-5678"]
いずれか1個の文字または半角数字にマッチする
[-az] or [az-]
[-09] or [09-] # 半角数字は0123456789のいずれか。
範囲を表すメタ文字の[]の前後に-をつけることで、いずれか1個の文字または半角数字を表すことができます。
文字を表す部分はazで表現しています。
以下では[az-]とすることで、aという文字だけをマッチさせています。
# <<~TEXT..TEXTの部分はヒアドキュメント
text = <<~TEXT
I have a pen
TEXT
# //がrubyでのREGEXPクラスのインスタンス
# scanメソッドは引数に指定した正規表現のパターンとマッチする部分を文字列からすべて取り出し、配列にして返す。
# マッチする部分がなければ、空の配列を返します。
# //の中に正規表現を入力してください。
p text.scan(/[-az]/)
#=> ["a", "a"]
直前の文字がn個以上、m個以下にマッチ
{n,m}
nとmにそれぞれ数字を指定することで、マッチさせる範囲を指定することができます。
{2, 4}とすれば、2個以上4個以下にマッチするという意味になりますね。
基本的には、他のメタ文字と組み合わせて使われます。
以下では、[a-z]{2,5}とすることで、3文字~5文字の組み合わせの英単語にマッチさせています。
# <<~TEXT..TEXTの部分はヒアドキュメント
text = <<~TEXT
I have a pen and apple
TEXT
# //がrubyでのREGEXPクラスのインスタンス
# scanメソッドは引数に指定した正規表現のパターンとマッチする部分を文字列からすべて取り出し、配列にして返す。
# マッチする部分がなければ、空の配列を返します。
# //の中に正規表現を入力してください。
p text.scan(/[a-z]{2,5}/)
#=> ["have", "pen", "and", "apple"]
ちょうどn文字
{n}
{n}のように単体で数字を指定すると、n文字ちょうどの文字列とヒットします。
{2}とすれば、ちょうど2文字の文字列とマッチすることになりますね。
以下では、[a-z]{5}とすることでappleという文字列とマッチしています。
# <<~TEXT..TEXTの部分はヒアドキュメント
text = <<~TEXT
I have a pen and apple
TEXT
# //がrubyでのREGEXPクラスのインスタンス
# scanメソッドは引数に指定した正規表現のパターンとマッチする部分を文字列からすべて取り出し、配列にして返す。
# マッチする部分がなければ、空の配列を返します。
# //の中に正規表現を入力してください。
p text.scan(/[a-z]{5}/)
#=> ["apple"]
AまたはBいずれかの1文字を表すメタ文字
[AB]
先ほどから出てきている[a-z]は、アルファベットのaからzまでの範囲でいずれかの1文字という表現を表しています。
ハイフンまたは括弧(開き)にマッチ
[-(]
ハイフンまたは括弧(閉じ)にマッチ
[-)]
先ほどのものと反対で、[]に-と)を指定すれば、ハイフンまたは括弧の閉じのいずれかにマッチするという意味になります。
以下では、二つある電話番号のうち、[-(][-)]とすることで括弧のついた電話番号とマッチさせています。
# <<~TEXT..TEXTの部分はヒアドキュメント
text = <<~TEXT
03(1234)5678
010-222-56789
TEXT
# //がrubyでのREGEXPクラスのインスタンス
# scanメソッドは引数に指定した正規表現のパターンとマッチする部分を文字列からすべて取り出し、配列にして返す。
# マッチする部分がなければ、空の配列を返します。
# //の中に正規表現を入力してください。
p text.scan(/\d{2}[-(]\d{4}[-)]\d{4}/)
#=> ["03(1234)5678"]
直前の文字が1個またはなし
?
?を使うことで、直前の文字が1個またはないことを表現できます。
例えば、[-]?とすれば、半角のハイフンが1個または半角のハイフンがないものとマッチするという意味になりますね。
以下の例では3つの単語のうち、/プ[-]?リン/とすることで、プ-リンとプリンだけマッチしています。
# <<~TEXT..TEXTの部分はヒアドキュメント
text = <<~TEXT
クリ-リン
クリリン
クリリ-ン
TEXT
# //がrubyでのREGEXPクラスのインスタンス
# scanメソッドは引数に指定した正規表現のパターンとマッチする部分を文字列からすべて取り出し、配列にして返す。
# マッチする部分がなければ、空の配列を返します。
# //の中に正規表現を入力してください。
p text.scan(/クリ[-]?リン/)
#=> ["クリ-リン", "クリリン"]
任意の1文字を表す
.
.を使うことで、直前に指定した文字に続く、あらゆる1文字とマッチさせることができます。
例えば、以下では/クリ.リン/とすることで、クリとリンの間にハイフンや全角/半角スペースがあってもマッチすることになりますね。
# <<~TEXT..TEXTの部分はヒアドキュメント
text = <<~TEXT
クリ-リン
クリリン
クリリ-ン
クリ リン
クリ リン
TEXT
# //がrubyでのREGEXPクラスのインスタンス
# scanメソッドは引数に指定した正規表現のパターンとマッチする部分を文字列からすべて取り出し、配列にして返す。
# マッチする部分がなければ、空の配列を返します。
# //の中に正規表現を入力してください。
p text.scan(/クリ.リン/)
#=> ["クリ-リン", "クリ リン", "クリ リン"]
任意の1文字なので、厳密に指定しなくてもよくなるため、正規表現をスッキリ書くことができるようになります。
メタ文字をエスケープする
「.」を扱う時、ファイルパスなどをマッチさせる際には注意しないと意図した挙動になりません。
例えば、「freelance.txt」「freelance_txt.txt」という文字列が、あったとしましょう。
その際、freelance.txtというテキストファイルを正規表現でマッチさせたい時に、/freelance.txt/とすると、freelance_txtという文字列もマッチしてしまいます。
# <<~TEXT..TEXTの部分はヒアドキュメント
text = <<~TEXT
freelance.txt
freelance_txt
TEXT
# //がrubyでのREGEXPクラスのインスタンス
# scanメソッドは引数に指定した正規表現のパターンとマッチする部分を文字列からすべて取り出し、配列にして返す。
# マッチする部分がなければ、空の配列を返します。
# //の中に正規表現を入力してください。
p text.scan(/freelance.txt/)
#=> ["freelance.txt", "freelance_txt"]
でも、「.」の直前にバックスラッシュをつけてエスケープさせれば、ちゃんと意図通りにfreelance.txtのみマッチします。
# <<~TEXT..TEXTの部分はヒアドキュメント
text = <<~TEXT
freelance.txt
freelance_txt
TEXT
# //がrubyでのREGEXPクラスのインスタンス
# scanメソッドは引数に指定した正規表現のパターンとマッチする部分を文字列からすべて取り出し、配列にして返す。
# マッチする部分がなければ、空の配列を返します。
# //の中に正規表現を入力してください。
p text.scan(/freelance\.txt/)
#=> ["freelance.txt"]
直前の文字が1文字以上
+
「+」を使うと、直前の文字が1文字以上である文字列とマッチさせることができます。
例えば、[a-z0-9]+のようにすれば、半角英数字が1文字以上という条件の文字列にマッチすることになりますね。
# <<~TEXT..TEXTの部分はヒアドキュメント
text = <<~TEXT
ps3
gba
TEXT
# //がrubyでのREGEXPクラスのインスタンス
# scanメソッドは引数に指定した正規表現のパターンとマッチする部分を文字列からすべて取り出し、配列にして返す。
# マッチする部分がなければ、空の配列を返します。
# //の中に正規表現を入力してください。
p text.scan(/[a-z0-9]+/)
#=> ["ps3", "gba"]
直前の文字が0文字以上
*
「*」にすると、直前に指定した文字が0文字以上の場合にもマッチさせることができます。
つまり、直前の文字が空の場合でもマッチするようになるので、「+」よりも広範囲にマッチさせることができるようになります。
ただし、広範囲にマッチする分、使い方を間違えると意図した挙動にならないので注意が必要です。
マッチする部分をキャプチャ(捕捉)する(パターンをグループ化するときにも使う)
()
「()」でメタ文字や文字列を囲むことにより、グループ化することができます。
組み合わせ次第でかなり複雑かつ精度の高い正規表現を扱えるようになるので、「[]」と合わせて使いこなせるようになるといいですね、
キャプチャした部分を置換するために参照する
$1 # テキストエディタで置換する用の書き方
\1 # プログラム内で置換する用の書き方
「()」でキャプチャ・グループ化した文字列を置換する際に使います。
プログラム内ではgsubメソッドと組み合わせて使われることが多いですね。
最短のマッチ結果を返す
*? # 最初に見つかった任意の文字が0個以上
+? # 最初に見つかった任意の文字が1個以上
メタ文字の「*」や「+」は直前の文字を検索した時に、最後に見つかった文字列を返すのが特徴。(最長マッチ)
「(.*)」だと>という文字列にヒットすれば全て返してきてしまうので、不要なdivタグまでマッチしてしまいます。
# <<~TEXT..TEXTの部分はヒアドキュメント
text = <<~TEXT
<div>今日はオムライスを食べた。
すごく美味しかった。</p></div>
TEXT
# //がrubyでのREGEXPクラスのインスタンス
# scanメソッドは引数に指定した正規表現のパターンとマッチする部分を文字列からすべて取り出し、配列にして返す。
# マッチする部分がなければ、空の配列を返します。
# //の中に正規表現を入力してください。
# p text.gsub(/([a-z0-9]).+/, '\1')
p text.scan(/<p.*>/)
#=>["<p>今日はオムライスを食べた。
すごく美味しかった。</p></div>"]
しかし、「(.*?)」とすれば最初にマッチした>だけ返すので結果、最初のpタグだけマッチするようになります。
# <<~TEXT..TEXTの部分はヒアドキュメント
text = <<~TEXT
<div><p>今日はオムライスを食べた。
<p>すごく美味しかった。</p></div>
TEXT
# //がrubyでのREGEXPクラスのインスタンス
# scanメソッドは引数に指定した正規表現のパターンとマッチする部分を文字列からすべて取り出し、配列にして返す。
# マッチする部分がなければ、空の配列を返します。
# //の中に正規表現を入力してください。
# p text.gsub(/([a-z0-9]).+/, '\1')
p text.scan(/<p.*?>/)
#=>["<p>", "<p>"]
上手に使い分けられるようになると、正規表現でたくさんの文字列にマッチさせることができるので、是非マスターしたいところですね。
指定した文字以外の任意の文字(否定クラス)
[^AB] # AでもなくBでもない任意の1文字
^ # 行頭を意味する
^(キャレット)は、通常だと行頭を意味するメタ文字ですが、[]の中で文字列の前に使用すると否定を表す文字クラスになります。
[^a]とすることで、a以外の任意の文字という意味になりますね。行末を意味する(ただし、改行文字は含まない)
$
こちらの$(ダラー)は単純に行末を意味するメタ文字になります。
タブ文字を意味する
\n
OR条件を意味する
|
ABC|DEF # ABCまたはDEFを表す
改行文字を意味する
\n
復帰文字を意味する(Windowsなど改行コードがCRLFのときなどに使う)
\r
慣れてきたなら覚えたい、正規表現〜中級編〜
任意のカタカナ1文字にマッチする
\p{katakana}
この\pという文字ですが、これはUnicode文字のプロパティを意味しています。
\p{katakana}とすることで、任意のカタカナ1文字とマッチさせることができます。
全角と半角の両方にマッチしますが、半角カナの場合「ポ」「ボ」のような濁音にはそのままだとマッチしないので、別途Unicode記号を指定する必要があります。
例えば、「パン」のような半角カナにマッチさせたければ、以下のように書く必要があるということになります。
\p{katakana}\u{ff39}
結構ややこしく、かなり奥が深いので興味のあるかたは、以下のサイトを参考に調べてみてください。
参考サイト
https://qiita.com/ymrl/items/b34c5493c9383633330b
スープなどの"ー(全角の長音)"にマッチする
\u{30fc}
メタ文字を組み合わせて複雑な正規表現を作る
正規表現同士をOR条件で連結する
\d{4}|[A-Z]{6} # 半角数字4桁またはA-Zいずれかのアルファベット大文字6文字にマッチ
「*」と「()」を組み合わせて使う
()* # ()の中のパターンが0回以上連続する
(\d{2}-\d{4})* # 2桁の半角数字-4桁の半角数字のパターンが0回以上連続する
「+」や「?」、{n,m}も同じように「()」と組み合わせて使うことができる。
正規表現のオンラインパフォーマンス確認ツール
Online regex tester and debuggerは正規表現のパフォーマンスの良し悪しをある程度判定できるオンラインツールです。
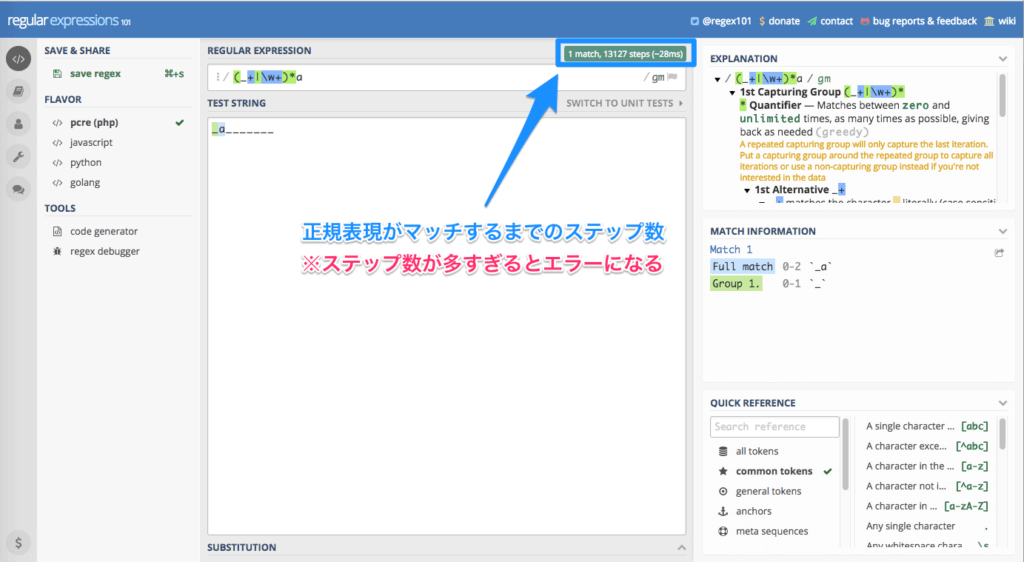
メタ文字の組み合わせ方によっては、サーバーに負担をかけてしまうほど処理速度が遅くなる場合があります。
そんな時に、Online regex tester and debuggerのようなサイトでパフォーマンスを確認すれば、自分の書いた正規表現がちゃんと効率的なのかどうかをざっくりと知ることができるので便利ですよね。
もちろん、仕事で使うコードをそのまま貼り付けるのはセキュリティの観点から見ても情報漏洩のリスクがあるので絶対ダメですよ!
Online regex tester and debuggerのサイトはこちら
最後に
一通り正規表現で使うメタ文字の意味を羅列してきましたが、難しく感じましたか?
いきなりすべてを覚えるのは難しいと思うので、少しずつ書いたり、他の人のコードを見ながらトライアンドエラーを繰り返せば身につくと思いますよ!
それではよきRubyライフを!




![[Rails]本番/検証環境でconfig.asset.compileをfalseにする時の注意点](https://breakthrough-tech.yuta-u.com/wp-content/uploads/2018/05/markus-spiske-666904-unsplash-150x150.jpg)